当期目录
2021,
(4):
1-7. doi: 10.3969/j.issn.1000-5641.2021.04.001
 摘要
摘要 HTML全文
HTML全文
摘要:
为了提高好氧反硝化菌的环境耐受性和脱氮效率, 采用聚乙烯醇(PVA)、海藻酸钠(SA)和稻壳粉作为载体对好氧反硝化菌进行固定化, 并对固定化颗粒的性能进行评价. 结果如下: 固定化颗粒最佳配比为12%聚乙烯醇(PVA)、8%海藻酸钠(SA)、0.5 g稻壳粉和10 mL菌液; 固定化颗粒具有较好的稳定性和传质性, 48 h的总氮(TN)去除率为89.35% ~ 90.12%. 固定化颗粒对pH值和转速具有良好的耐受性, pH值为11时, TN去除率为90%; 120 r/min时TN和NH4+-N去除率最高, 分别为91.29%和93.30%; 固定化颗粒不耐低温(10℃和15℃), 在10℃时, TN去除率仅为20%左右; 但是在30℃时, TN去除率可达90.59%.
为了提高好氧反硝化菌的环境耐受性和脱氮效率, 采用聚乙烯醇(PVA)、海藻酸钠(SA)和稻壳粉作为载体对好氧反硝化菌进行固定化, 并对固定化颗粒的性能进行评价. 结果如下: 固定化颗粒最佳配比为12%聚乙烯醇(PVA)、8%海藻酸钠(SA)、0.5 g稻壳粉和10 mL菌液; 固定化颗粒具有较好的稳定性和传质性, 48 h的总氮(TN)去除率为89.35% ~ 90.12%. 固定化颗粒对pH值和转速具有良好的耐受性, pH值为11时, TN去除率为90%; 120 r/min时TN和NH4+-N去除率最高, 分别为91.29%和93.30%; 固定化颗粒不耐低温(10℃和15℃), 在10℃时, TN去除率仅为20%左右; 但是在30℃时, TN去除率可达90.59%.



2021,
(4):
8-16. doi: 10.3969/j.issn.1000-5641.2021.04.002
摘要:
为建立集成化多塘湿地(Multi-pond Constructed Wetlands, MPCWs)多维度评价体系, 选取污染物净化能力、污水蓄积性能、植被生态修复效果及经济成本为指标, 采用等级评价方法评估了多塘湿地工程的综合效果. 结果表明: 大规模集成化多塘湿地应用于面源污染控制, 有助于污染物的截留. 净化后的中水便于农村农业就近用水, 可实现节水减污、水资源调配及污水回用; 多塘湿地植被配置有助于植被生态修复, 有助于污水净化. 基于多塘湿地不同功能需求, 综合考虑经济成本及深水湿地安全隐患大等因素, 提出了不同类型多塘湿地的应用建议. 水量小、污染重、人口多的区域可匹配浅水表流湿地; 水量大、污染重、人口少的区域可匹配生态浮床湿地. 兼顾土地资源禀赋、污染源结构、农村农业用水资源分配等多种因素可实现不同类型多塘湿地的科学应用.
为建立集成化多塘湿地(Multi-pond Constructed Wetlands, MPCWs)多维度评价体系, 选取污染物净化能力、污水蓄积性能、植被生态修复效果及经济成本为指标, 采用等级评价方法评估了多塘湿地工程的综合效果. 结果表明: 大规模集成化多塘湿地应用于面源污染控制, 有助于污染物的截留. 净化后的中水便于农村农业就近用水, 可实现节水减污、水资源调配及污水回用; 多塘湿地植被配置有助于植被生态修复, 有助于污水净化. 基于多塘湿地不同功能需求, 综合考虑经济成本及深水湿地安全隐患大等因素, 提出了不同类型多塘湿地的应用建议. 水量小、污染重、人口多的区域可匹配浅水表流湿地; 水量大、污染重、人口少的区域可匹配生态浮床湿地. 兼顾土地资源禀赋、污染源结构、农村农业用水资源分配等多种因素可实现不同类型多塘湿地的科学应用.






2021,
(4):
17-25. doi: 10.3969/j.issn.1000-5641.2021.04.003
摘要:
在分析不同低影响开发技术(Low Impact Development, LID)措施的径流削减效果的基础上, 提出了基于LID径流削减效率的LID指数的模型, 进而设计了LID设施选择图, 以根据建成区径流污染削减目标而快速选择适宜的LID设施类型及不同LID设施类型的比例. 结果表明, 随着LID指数增加, 雨水径流量及雨水径流污染物呈类似指数形式降低, 且LID指数越大, LID径流削减率越大, 但是径流削减的边际效应逐渐降低; 该模型灵活性较高, 具有探索应用意义.
在分析不同低影响开发技术(Low Impact Development, LID)措施的径流削减效果的基础上, 提出了基于LID径流削减效率的LID指数的模型, 进而设计了LID设施选择图, 以根据建成区径流污染削减目标而快速选择适宜的LID设施类型及不同LID设施类型的比例. 结果表明, 随着LID指数增加, 雨水径流量及雨水径流污染物呈类似指数形式降低, 且LID指数越大, LID径流削减率越大, 但是径流削减的边际效应逐渐降低; 该模型灵活性较高, 具有探索应用意义.




2021,
(4):
26-38. doi: 10.3969/j.issn.1000-5641.2021.04.004
摘要:
“水体污染控制与治理”科技重大专项(简称水专项)自“十一五”以来研发了20余项生态修复关键技术, 为解决单项技术在湖滨带生态修复过程中应用成效局限性问题, 基于提升土壤稳定性、改善湿地生境、恢复修复区水生植被、实现长效运行管理等技术需求, 选择生态修复区迎风岸坡重建与消浪挡藻技术, 基底快速沉降-持久稳定-水质底质改善技术, 敞水区水生植被多层次重建技术, 水陆交错带植被优化配置与稳定化技术, 水生植被资源化利用与生态修复长效运行管理技术等, 凝练形成以“湖滨带现状调查、健康评价与诊断—生境改善—水生植被恢复—长效运行管理”为集成模式的太湖不同类型湖滨带水生植被恢复成套技术. 其中, 大堤型湖滨带植被恢复成套技术在太湖竺山湾应用成效显著, 可消减64%风浪, 植被覆盖率达到30%以上; 缓坡型湖滨带植被恢复成套技术在太湖贡湖湾应用成效显著, 水生植物覆盖度达到57%, 水体透明度 > 110 cm, 生物多样性指数大幅提高. 为太湖湖滨带水生植被恢复与水质改善工作提供了实践依据.
“水体污染控制与治理”科技重大专项(简称水专项)自“十一五”以来研发了20余项生态修复关键技术, 为解决单项技术在湖滨带生态修复过程中应用成效局限性问题, 基于提升土壤稳定性、改善湿地生境、恢复修复区水生植被、实现长效运行管理等技术需求, 选择生态修复区迎风岸坡重建与消浪挡藻技术, 基底快速沉降-持久稳定-水质底质改善技术, 敞水区水生植被多层次重建技术, 水陆交错带植被优化配置与稳定化技术, 水生植被资源化利用与生态修复长效运行管理技术等, 凝练形成以“湖滨带现状调查、健康评价与诊断—生境改善—水生植被恢复—长效运行管理”为集成模式的太湖不同类型湖滨带水生植被恢复成套技术. 其中, 大堤型湖滨带植被恢复成套技术在太湖竺山湾应用成效显著, 可消减64%风浪, 植被覆盖率达到30%以上; 缓坡型湖滨带植被恢复成套技术在太湖贡湖湾应用成效显著, 水生植物覆盖度达到57%, 水体透明度 > 110 cm, 生物多样性指数大幅提高. 为太湖湖滨带水生植被恢复与水质改善工作提供了实践依据.









2021,
(4):
39-45. doi: 10.3969/j.issn.1000-5641.2021.04.005
摘要:
梳理了国内外排污许可制度的发展历程, 分析总结了国家水体污染控制与治理科技重大专项(简称“水专项”)实施初期太湖流域排污许可管理体系存在的问题和科技需求. 根据对“十一五”、“十二五”水专项太湖技术成果的梳理总结, 从控制单元划分、控制单元污染负荷核定、控制单元水环境容量核算、重点行业水污染控制与治理技术评估、排污许可量分配和证后动态监管角度集成形成工业点源排污许可管理成套技术. 同时阐释了成套技术在太湖流域的应用成效, 以期为太湖流域排污许可管理制度的实施提供经验和借鉴.
梳理了国内外排污许可制度的发展历程, 分析总结了国家水体污染控制与治理科技重大专项(简称“水专项”)实施初期太湖流域排污许可管理体系存在的问题和科技需求. 根据对“十一五”、“十二五”水专项太湖技术成果的梳理总结, 从控制单元划分、控制单元污染负荷核定、控制单元水环境容量核算、重点行业水污染控制与治理技术评估、排污许可量分配和证后动态监管角度集成形成工业点源排污许可管理成套技术. 同时阐释了成套技术在太湖流域的应用成效, 以期为太湖流域排污许可管理制度的实施提供经验和借鉴.

2021,
(4):
46-54. doi: 10.3969/j.issn.1000-5641.2021.04.006
摘要:
为了解决城市河道治理过程中氮营养盐去除难题, 城市河道体系中溶解性有机质 (DOM) 对反硝化过程的影响作用值得重视. 研究表明, 河道沉积物中DOM的腐殖化程度较低、芳香性弱, 以小分子的富里酸为主, 其浓度平均为 (1868.5 ± 63.2) mg/kg. 与空白组相比, DOM可以促进反硝化过程, 对TN和NO3–-N去除率分别提升了7.24% ± 0.36%和23.52% ± 1.17%, 而DOM协同乙酸盐组对TN和NO3–-N的去除效果更好, 分别可以达到74.48% ± 1.29%和98.62% ± 0.07%. 微生物分析表明, DOM组的菌群多样性和丰富度均高于空白组, 但其中的异养反硝化菌属Pseudomonas和Brevundimonas以及nirK型反硝化菌属Paracoccus的丰度均低于DOM协同乙酸盐组. 此外, DOM运行体系中NH4+-N浓度维持较高的水平 (大于3.7 mg/L), 而且含有DOM体系中与异化硝酸盐还原成铵 (DNRA) 功能相关的厌氧粘细菌 (Anaeromyxobacter), 其相对丰度明显增加, 推测DOM在促进反硝化的同时诱导了DNRA过程的发生.
为了解决城市河道治理过程中氮营养盐去除难题, 城市河道体系中溶解性有机质 (DOM) 对反硝化过程的影响作用值得重视. 研究表明, 河道沉积物中DOM的腐殖化程度较低、芳香性弱, 以小分子的富里酸为主, 其浓度平均为 (1868.5 ± 63.2) mg/kg. 与空白组相比, DOM可以促进反硝化过程, 对TN和NO3–-N去除率分别提升了7.24% ± 0.36%和23.52% ± 1.17%, 而DOM协同乙酸盐组对TN和NO3–-N的去除效果更好, 分别可以达到74.48% ± 1.29%和98.62% ± 0.07%. 微生物分析表明, DOM组的菌群多样性和丰富度均高于空白组, 但其中的异养反硝化菌属Pseudomonas和Brevundimonas以及nirK型反硝化菌属Paracoccus的丰度均低于DOM协同乙酸盐组. 此外, DOM运行体系中NH4+-N浓度维持较高的水平 (大于3.7 mg/L), 而且含有DOM体系中与异化硝酸盐还原成铵 (DNRA) 功能相关的厌氧粘细菌 (Anaeromyxobacter), 其相对丰度明显增加, 推测DOM在促进反硝化的同时诱导了DNRA过程的发生.





2021,
(4):
55-63. doi: 10.3969/j.issn.1000-5641.2021.04.007
摘要:
以“十一五”和“十二五”期间的A2/O升级改造技术成果为基础, 结合当前运行良好且具有代表性的改良A2/O工艺, 从原位优化改造和深度处理等方面总结了高排放标准下城镇污水厂A2/O工艺升级改造的技术对策. 介绍了具有代表性的A2/O升级改造示范工程的运行情况, 并对A2/O工艺的优化和推广使用提供建议.
以“十一五”和“十二五”期间的A2/O升级改造技术成果为基础, 结合当前运行良好且具有代表性的改良A2/O工艺, 从原位优化改造和深度处理等方面总结了高排放标准下城镇污水厂A2/O工艺升级改造的技术对策. 介绍了具有代表性的A2/O升级改造示范工程的运行情况, 并对A2/O工艺的优化和推广使用提供建议.



2021,
(4):
64-71. doi: 10.3969/j.issn.1000-5641.2021.04.008
摘要:
以大莲湖为研究对象, 以大莲湖周边水体的水文、水质的调查数据为依据, 研究了大莲湖示范区水系水环境现状以及地表径流污染情况. 结果表明, 金泽水源地水质大部分能够满足地表水Ⅲ类水标准, 但部分指标存在季节性差异, 使得金泽水源地水质总体上不能稳定达标. 大莲湖示范区周围水体多为缓流水体(流速0 ~ 0.03 m/s), 透明度较低, 水体呈中性偏弱碱性(pH = 6.63 ~ 9.67), 易生成水华. 各个采样点氮磷营养盐污染较为严重, 且季节性差异明显, 春夏季水质较好(Ⅱ类—Ⅲ类)、秋冬部分水体在某些时间段呈现Ⅴ类水. 大莲湖示范区雨水径流浓度有明显的初期效应, 各下垫面氮磷的平均浓度远高于地表水Ⅴ类标准, 污染较为严重.
以大莲湖为研究对象, 以大莲湖周边水体的水文、水质的调查数据为依据, 研究了大莲湖示范区水系水环境现状以及地表径流污染情况. 结果表明, 金泽水源地水质大部分能够满足地表水Ⅲ类水标准, 但部分指标存在季节性差异, 使得金泽水源地水质总体上不能稳定达标. 大莲湖示范区周围水体多为缓流水体(流速0 ~ 0.03 m/s), 透明度较低, 水体呈中性偏弱碱性(pH = 6.63 ~ 9.67), 易生成水华. 各个采样点氮磷营养盐污染较为严重, 且季节性差异明显, 春夏季水质较好(Ⅱ类—Ⅲ类)、秋冬部分水体在某些时间段呈现Ⅴ类水. 大莲湖示范区雨水径流浓度有明显的初期效应, 各下垫面氮磷的平均浓度远高于地表水Ⅴ类标准, 污染较为严重.







2021,
(4):
72-80. doi: 10.3969/j.issn.1000-5641.2021.04.009
摘要:
以“十三五”国家重大水专项上海市青浦区金泽水源地雨水径流污染防控技术示范区——大莲湖为研究区域, 针对示范区内岸带的类型及坡度、岸带土壤的性质和土著植物的种类进行系统的调研分析, 为后续河岸带地表径流污染阻控技术研发提供基础数据资料支撑. 分析结果表明: 示范区周边主要护岸类型为近自然和硬质护岸, 以缓坡为主; 水生植物和陆生植物分别以荷花、芦苇和草本植物居多. 此外, 研究区采样点中, 临近农田土壤全氮含量平均值在0.95 g/kg上下波动, 高于进水闸附近土壤的0.42 g/kg; 临近居民生活区、鱼塘养殖和农田区的土壤全磷含量多在1.58 g/kg以上, 高于湖岸护坡土壤的1.10 g/kg; 有机质平均含量为11.30 g/kg, 其中植物密布区有机质含量较高, 表明当地的鱼塘养殖业以及农业对土壤环境造成了一定污染.
以“十三五”国家重大水专项上海市青浦区金泽水源地雨水径流污染防控技术示范区——大莲湖为研究区域, 针对示范区内岸带的类型及坡度、岸带土壤的性质和土著植物的种类进行系统的调研分析, 为后续河岸带地表径流污染阻控技术研发提供基础数据资料支撑. 分析结果表明: 示范区周边主要护岸类型为近自然和硬质护岸, 以缓坡为主; 水生植物和陆生植物分别以荷花、芦苇和草本植物居多. 此外, 研究区采样点中, 临近农田土壤全氮含量平均值在0.95 g/kg上下波动, 高于进水闸附近土壤的0.42 g/kg; 临近居民生活区、鱼塘养殖和农田区的土壤全磷含量多在1.58 g/kg以上, 高于湖岸护坡土壤的1.10 g/kg; 有机质平均含量为11.30 g/kg, 其中植物密布区有机质含量较高, 表明当地的鱼塘养殖业以及农业对土壤环境造成了一定污染.








2021,
(4):
81-89. doi: 10.3969/j.issn.1000-5641.2021.04.010
摘要:
选取了上海环城绿带中30个水体, 以现场实测数据和解译的缓冲区土地利用类型为基础, 综合运用马尔科夫转移矩阵和相关性分析, 揭示了环城绿带的土地利用变化规律及其与水质的响应关系. 结果显示: 绿带水体历年以Ⅳ类—劣Ⅴ类为主, 劣Ⅴ类水体占比呈逐年下降的趋势; 缓冲区内以建设用地、林地和草地为主, 三者合计占比约84.37%; 以建设用地的减少和裸地增加为主, 两者分别占总减少面积的48.95%和总增加面积的50.85%; 在300 m缓冲区尺度上, 草地对DO、Chla呈现正效应; 在500 m尺度上, 裸地是引起CODMn恶化的主要因素, 而耕地在两个尺度均与多个污染指标呈正相关.
选取了上海环城绿带中30个水体, 以现场实测数据和解译的缓冲区土地利用类型为基础, 综合运用马尔科夫转移矩阵和相关性分析, 揭示了环城绿带的土地利用变化规律及其与水质的响应关系. 结果显示: 绿带水体历年以Ⅳ类—劣Ⅴ类为主, 劣Ⅴ类水体占比呈逐年下降的趋势; 缓冲区内以建设用地、林地和草地为主, 三者合计占比约84.37%; 以建设用地的减少和裸地增加为主, 两者分别占总减少面积的48.95%和总增加面积的50.85%; 在300 m缓冲区尺度上, 草地对DO、Chla呈现正效应; 在500 m尺度上, 裸地是引起CODMn恶化的主要因素, 而耕地在两个尺度均与多个污染指标呈正相关.






2021,
(4):
90-98. doi: 10.3969/j.issn.1000-5641.2021.04.011
摘要:
总结了不同类型纳米材料对藻华控制的作用机制最新研究进展, 系统分析了环境因子对纳米材料调控营养盐迁移转化以及细胞毒性过程的影响. 并在此基础上对纳米材料的固定化研究提出展望, 以期实现纳米材料功能化和对其环境风险的精确管控, 为藻华治理提供新的解决思路.
总结了不同类型纳米材料对藻华控制的作用机制最新研究进展, 系统分析了环境因子对纳米材料调控营养盐迁移转化以及细胞毒性过程的影响. 并在此基础上对纳米材料的固定化研究提出展望, 以期实现纳米材料功能化和对其环境风险的精确管控, 为藻华治理提供新的解决思路.

2021,
(4):
99-108. doi: 10.3969/j.issn.1000-5641.2021.04.012
摘要:
北三河流域是京津冀地区的重要水源地, 恰当分析流域水源供给时空变化及驱动因素对维持生态系统安全与稳定意义重大. 基于气象、土地利用及土壤等数据, 利用InVEST模型的产水模块分析了北三河流域2000—2017年水源供给量的时空变化特征, 通过情景模拟探讨了气候与土地利用变化对流域水源供给能力变化的贡献程度. 结果表明, 2000—2017年, 北三河流域年均水源供给量为17.8 × 108 m3, 其年际变化呈增加趋势, 增长率为1.03 × 108 m3/a. 水源供给量在空间上呈南高北低的分布格局, 南北部的平均产水深度分别为70.85 mm和8.83 mm, 水源供给高值区由东南泃河和还乡河流域向西南温河与永定北河流域转移. 从不同的土地利用类型来看, 单位面积水源供给能力由高到低为: 建设用地 > 耕地 > 水域 > 未利用地 > 林地 > 草地. 2000—2015年, 耕地的水源供给量最高, 占流域水源供给总量的51.3%, 而建设用地水源供给量增长幅度最大, 达到144.3%. 情景模拟结果表明, 气候和土地利用变化对水源供给量增加的贡献率分别为70.7%和29.3%, 降水量的激增起到主导作用.
北三河流域是京津冀地区的重要水源地, 恰当分析流域水源供给时空变化及驱动因素对维持生态系统安全与稳定意义重大. 基于气象、土地利用及土壤等数据, 利用InVEST模型的产水模块分析了北三河流域2000—2017年水源供给量的时空变化特征, 通过情景模拟探讨了气候与土地利用变化对流域水源供给能力变化的贡献程度. 结果表明, 2000—2017年, 北三河流域年均水源供给量为17.8 × 108 m3, 其年际变化呈增加趋势, 增长率为1.03 × 108 m3/a. 水源供给量在空间上呈南高北低的分布格局, 南北部的平均产水深度分别为70.85 mm和8.83 mm, 水源供给高值区由东南泃河和还乡河流域向西南温河与永定北河流域转移. 从不同的土地利用类型来看, 单位面积水源供给能力由高到低为: 建设用地 > 耕地 > 水域 > 未利用地 > 林地 > 草地. 2000—2015年, 耕地的水源供给量最高, 占流域水源供给总量的51.3%, 而建设用地水源供给量增长幅度最大, 达到144.3%. 情景模拟结果表明, 气候和土地利用变化对水源供给量增加的贡献率分别为70.7%和29.3%, 降水量的激增起到主导作用.





2021,
(4):
109-120. doi: 10.3969/j.issn.1000-5641.2021.04.013
摘要:
针对我国南方红壤(江西鹰潭孙家坝小流域)4种不同土地利用类型, 在2019年6—10月开展了室内土壤温湿度控制实验, 采用温室气体分析仪(Picarro-G2508)结合静态箱法对土壤温室气体(CO2、CH4、N2O)排放通量进行同步实时监测, 以研究全球气候变化背景下不同土地利用类型土壤温室气体排放差异及其对温湿度的响应. 结果显示, 4种土地利用类型土壤的全球增温潜势(global warming potential, GWP)从高到低依次为稻田、橘园、林地、旱地, 表明稻田土壤温室气体排放对全球变暖贡献最大. 温控实验中, 土壤呼吸(CO2排放)与土壤温度呈显著正指数相关关系(p < 0.01), 且4种土地利用类型土壤呼吸的温度敏感系数Q10值分别为林地2.61、旱地2.51、橘园3.12、稻田3.17. 其中, 稻田土壤呼吸的温度敏感度最高, 表明稻田土壤具有较高的CO2排放潜力, 而CH4、N2O排放与土壤温度的相关性不显著. 湿度控制实验中, 土壤CO2排放随土壤湿度增加而先升高后降低, 并在土壤湿度20% GWC (gravity water content)时达到最大; 稻田土壤CH4排放与土壤湿度正相关(R2 = 0.8875), 但其他3种土地利用类型土壤CH4排放与土壤湿度不相关; 4种土地利用类型土壤N2O排放通量均随土壤湿度的增加呈先增后减趋势, 并在土壤湿度为25% GWC时达到峰值.
针对我国南方红壤(江西鹰潭孙家坝小流域)4种不同土地利用类型, 在2019年6—10月开展了室内土壤温湿度控制实验, 采用温室气体分析仪(Picarro-G2508)结合静态箱法对土壤温室气体(CO2、CH4、N2O)排放通量进行同步实时监测, 以研究全球气候变化背景下不同土地利用类型土壤温室气体排放差异及其对温湿度的响应. 结果显示, 4种土地利用类型土壤的全球增温潜势(global warming potential, GWP)从高到低依次为稻田、橘园、林地、旱地, 表明稻田土壤温室气体排放对全球变暖贡献最大. 温控实验中, 土壤呼吸(CO2排放)与土壤温度呈显著正指数相关关系(p < 0.01), 且4种土地利用类型土壤呼吸的温度敏感系数Q10值分别为林地2.61、旱地2.51、橘园3.12、稻田3.17. 其中, 稻田土壤呼吸的温度敏感度最高, 表明稻田土壤具有较高的CO2排放潜力, 而CH4、N2O排放与土壤温度的相关性不显著. 湿度控制实验中, 土壤CO2排放随土壤湿度增加而先升高后降低, 并在土壤湿度20% GWC (gravity water content)时达到最大; 稻田土壤CH4排放与土壤湿度正相关(R2 = 0.8875), 但其他3种土地利用类型土壤CH4排放与土壤湿度不相关; 4种土地利用类型土壤N2O排放通量均随土壤湿度的增加呈先增后减趋势, 并在土壤湿度为25% GWC时达到峰值.






2021,
(4):
121-133. doi: 10.3969/j.issn.1000-5641.2021.04.014
 PDF 4817KB
PDF 4817KB
摘要:
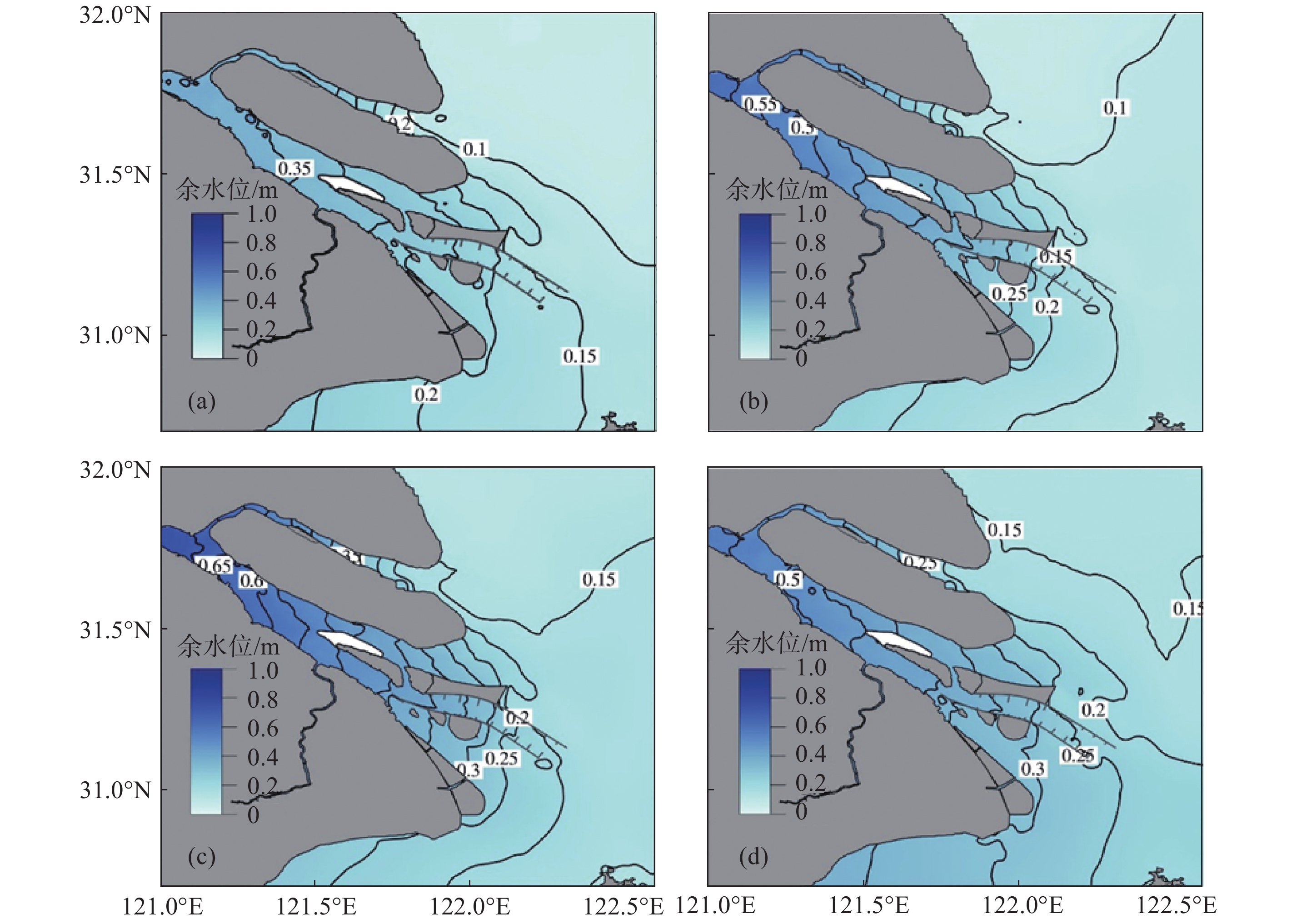
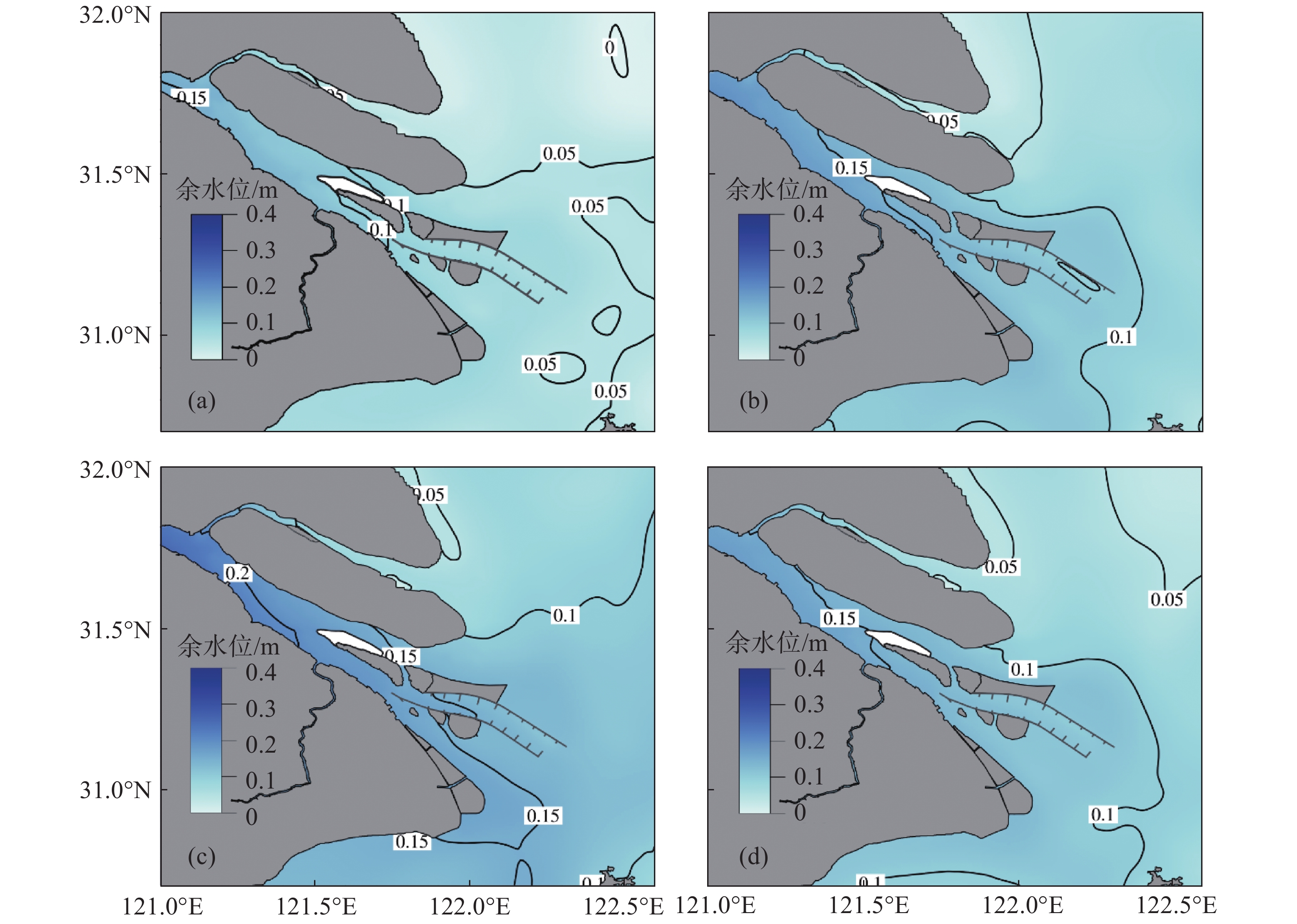
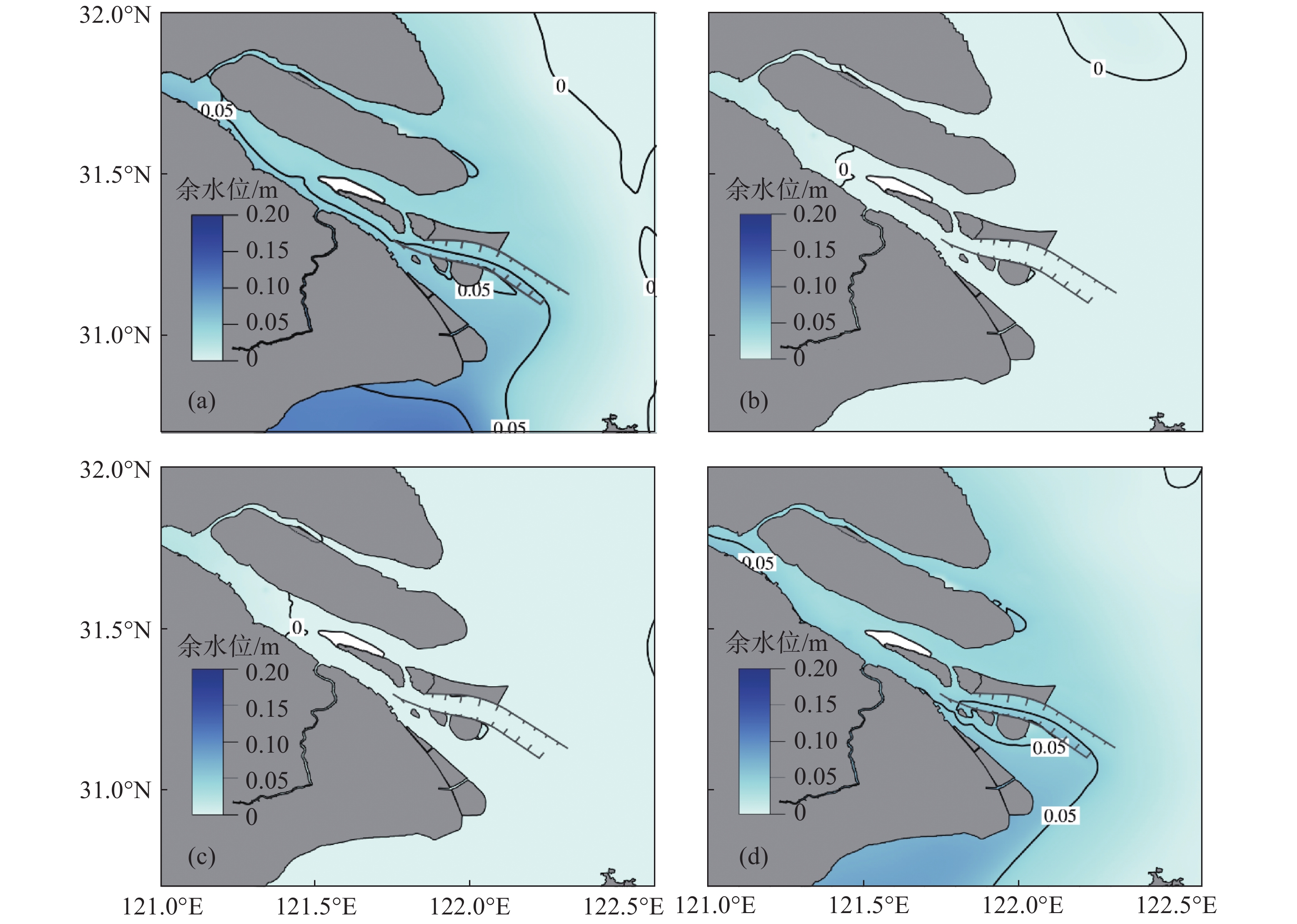
应用严格验证过的河口海岸三维数值模型, 模拟了长江口余水位的时空变化, 分析径流、潮汐和风应力对余水位的影响, 揭示了余水位变化的动力机制. 长江河口余水位的空间分布和随时间变化过程主要是受径流影响, 其次是受风的影响. 余水位上游大于下游. 全年最高余水位出现在9月, 徐六泾、崇西、南门、堡镇和深水航道北导堤东端分别为0.861 m、0.754 m、0.629 m、0.554 m和0.298 m. 最低余水位徐六泾和崇西出现在1月, 分别为0.420 m和0.391 m; 南门和堡镇出现在2月, 分别为0.313 m和0.291 m; 深水航道北导堤东端出现在4月, 量值为0.111 m. 北支余水位低于南支, 原因在于进入北支的径流量少. 南港的余水位大于北港, 同一河道内南侧的余水位大于北侧, 原因在于径流受科氏力作用右偏. 对比仅有径流、潮汐和风的数值试验结果, 对余水位作用最大的是径流, 其次是潮汐, 最小的是风. 月平均径流量7月达到最大, 会导致最高余水位, 但期间为东南风, 产生的余水位十分微小. 9月盛行的北风产生向陆的Ekman水体输运, 会引起河口余水位上升, 且期间径流量仍处于高值区, 两者相互作用, 导致整个河口全年最高余水位出现在9月.
应用严格验证过的河口海岸三维数值模型, 模拟了长江口余水位的时空变化, 分析径流、潮汐和风应力对余水位的影响, 揭示了余水位变化的动力机制. 长江河口余水位的空间分布和随时间变化过程主要是受径流影响, 其次是受风的影响. 余水位上游大于下游. 全年最高余水位出现在9月, 徐六泾、崇西、南门、堡镇和深水航道北导堤东端分别为0.861 m、0.754 m、0.629 m、0.554 m和0.298 m. 最低余水位徐六泾和崇西出现在1月, 分别为0.420 m和0.391 m; 南门和堡镇出现在2月, 分别为0.313 m和0.291 m; 深水航道北导堤东端出现在4月, 量值为0.111 m. 北支余水位低于南支, 原因在于进入北支的径流量少. 南港的余水位大于北港, 同一河道内南侧的余水位大于北侧, 原因在于径流受科氏力作用右偏. 对比仅有径流、潮汐和风的数值试验结果, 对余水位作用最大的是径流, 其次是潮汐, 最小的是风. 月平均径流量7月达到最大, 会导致最高余水位, 但期间为东南风, 产生的余水位十分微小. 9月盛行的北风产生向陆的Ekman水体输运, 会引起河口余水位上升, 且期间径流量仍处于高值区, 两者相互作用, 导致整个河口全年最高余水位出现在9月.











2021,
(4):
134-144. doi: 10.3969/j.issn.1000-5641.2021.04.015
摘要:
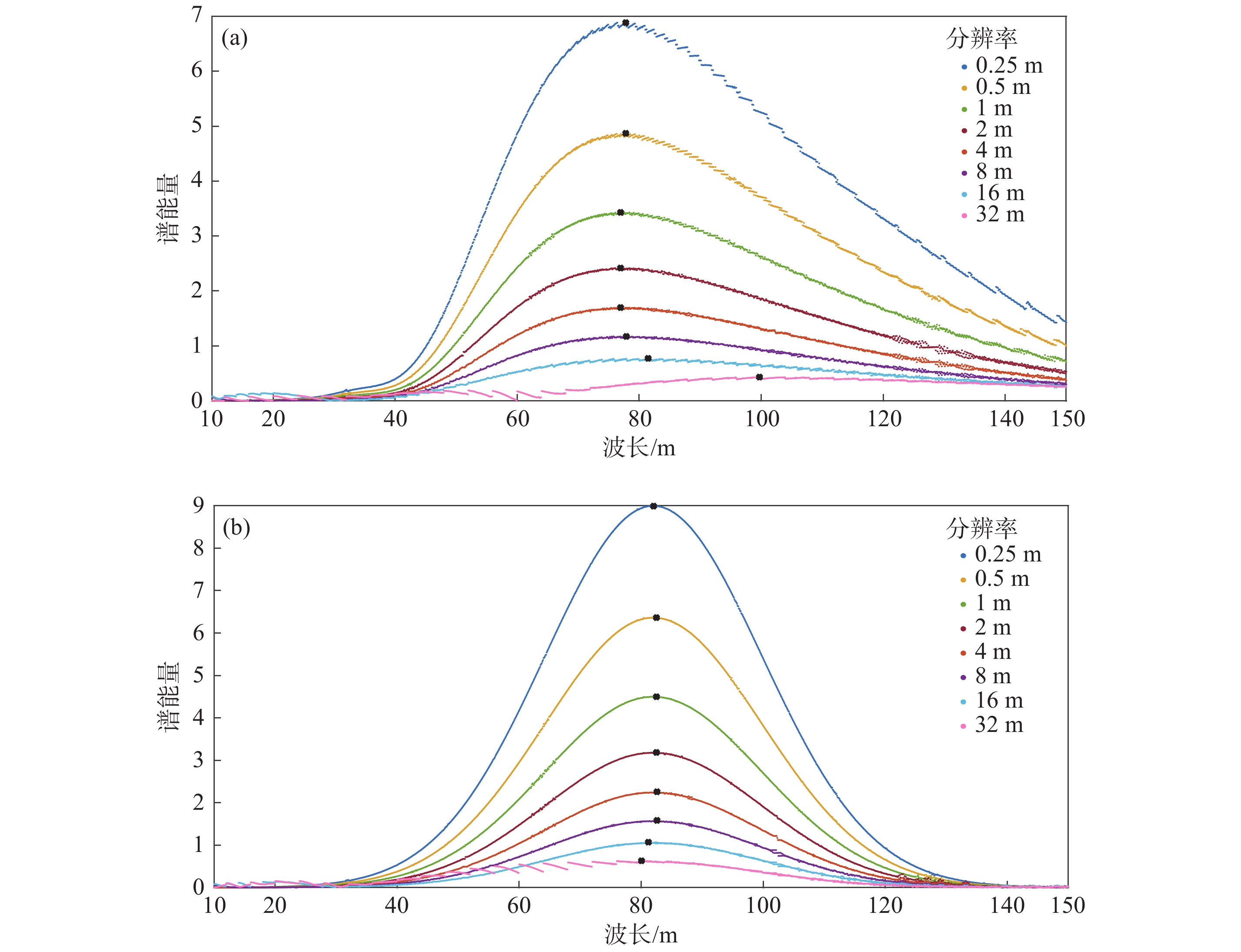
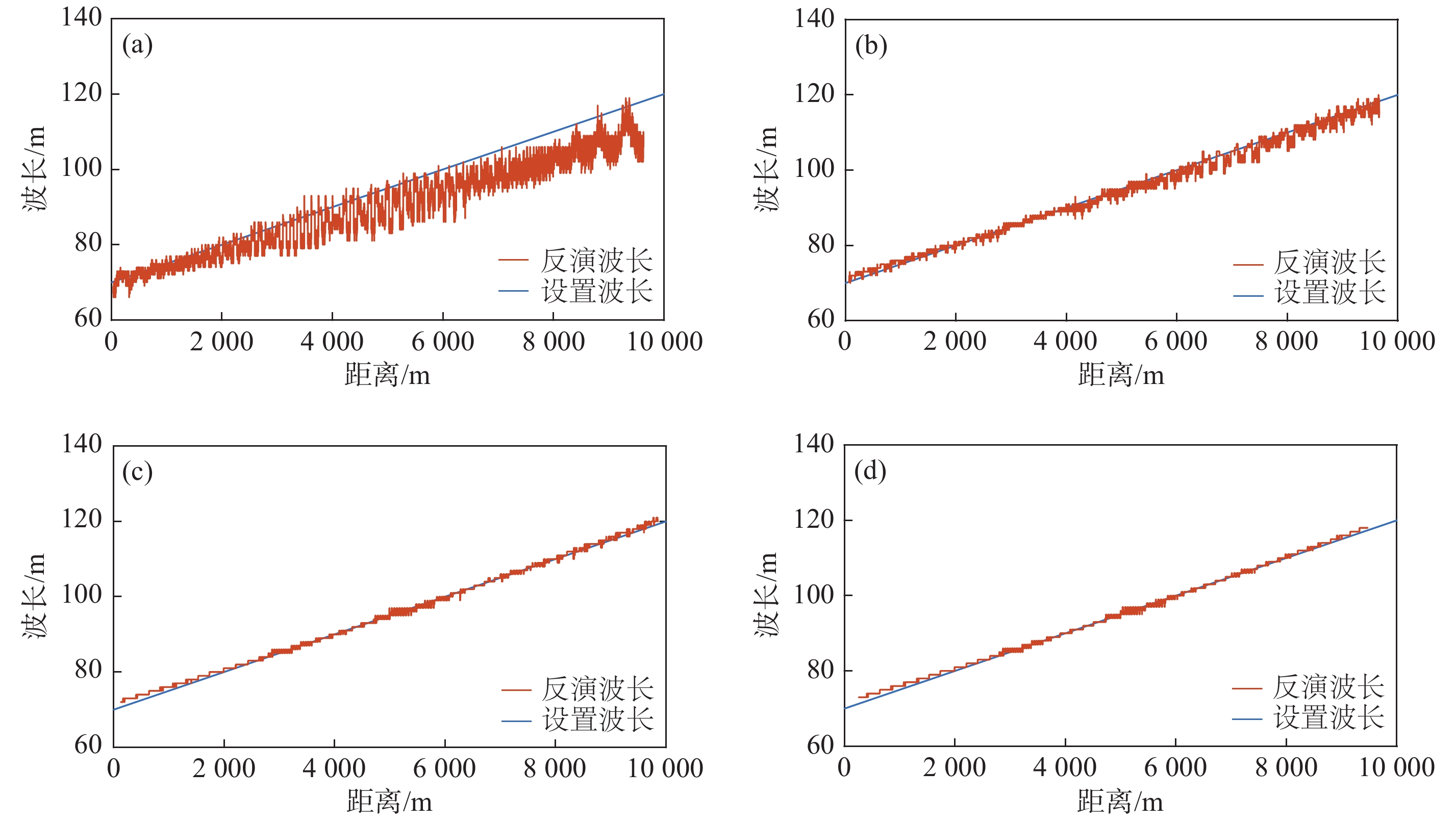
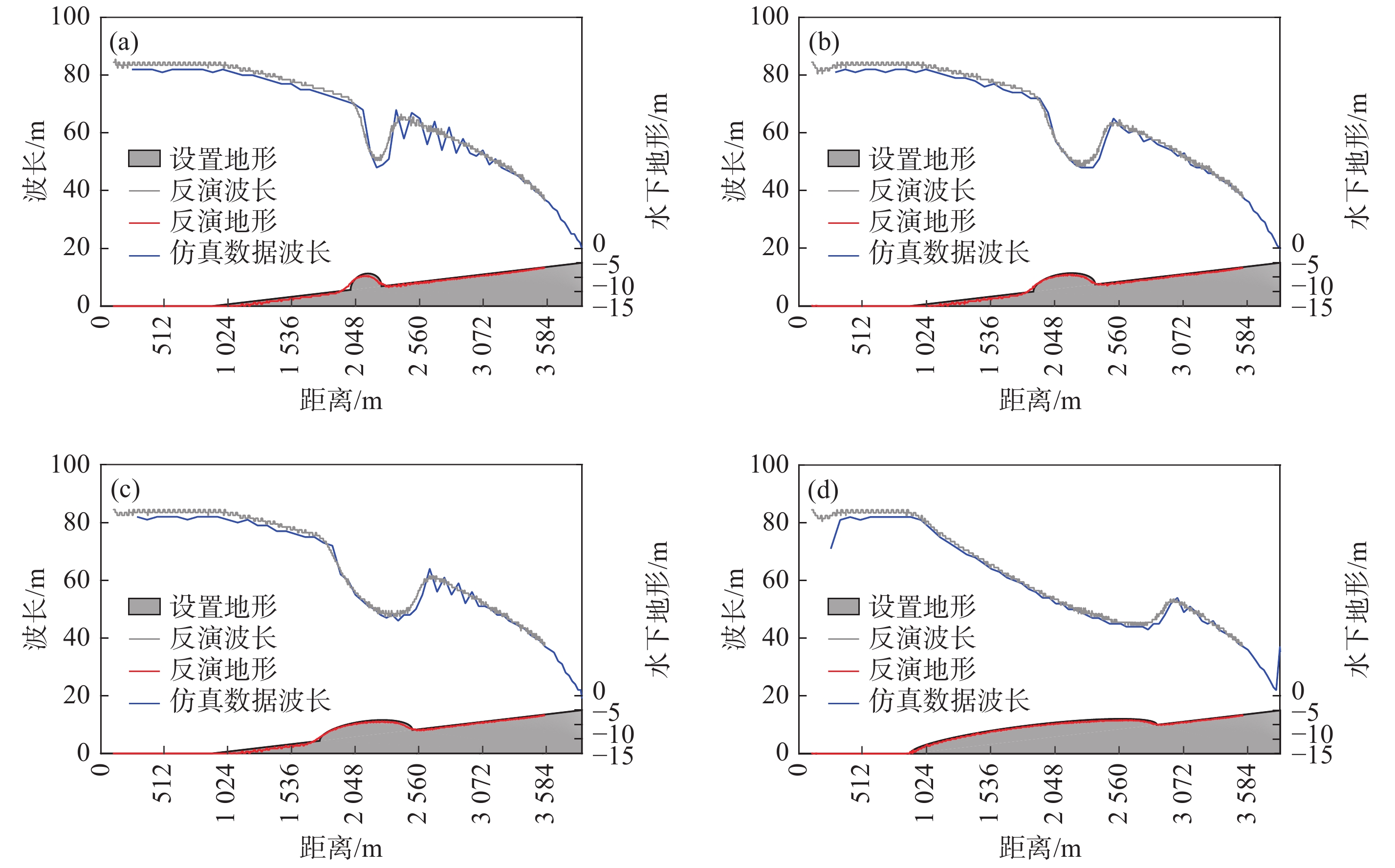
利用海浪造成的遥感影像波纹状特征, 可以基于小波方法反演海浪波长, 进而利用海浪波长随水深变浅而变短的特点反演浅海水深. 选择复Morlet小波方法, 采用理想波面数据和FUNWAVE模式数值模拟的波面数据代替遥感资料进行仿真研究, 讨论资料分辨率和子图分割对波长及水深反演的影响. 理想波面数据反演波长的结果表明, 在波长空间无变化的情况下, 子图长度大于波长、子图内均匀分布的资料点数在9个以上时, 资料分辨率对海浪波长反演结果基本无影响, 可以用波长能量谱解释其原因; 在波长空间变化的情况下, 子图长度大于2倍波长、每个波长内资料点数在4个以上, 可以得到较好的波长反演效果. 数值模拟波面数据反演波长对子图长度和资料点数也有类似的要求, 水深反演误差在子图尺度太大时略有增大, 随资料分辨率降低也略有增大.
利用海浪造成的遥感影像波纹状特征, 可以基于小波方法反演海浪波长, 进而利用海浪波长随水深变浅而变短的特点反演浅海水深. 选择复Morlet小波方法, 采用理想波面数据和FUNWAVE模式数值模拟的波面数据代替遥感资料进行仿真研究, 讨论资料分辨率和子图分割对波长及水深反演的影响. 理想波面数据反演波长的结果表明, 在波长空间无变化的情况下, 子图长度大于波长、子图内均匀分布的资料点数在9个以上时, 资料分辨率对海浪波长反演结果基本无影响, 可以用波长能量谱解释其原因; 在波长空间变化的情况下, 子图长度大于2倍波长、每个波长内资料点数在4个以上, 可以得到较好的波长反演效果. 数值模拟波面数据反演波长对子图长度和资料点数也有类似的要求, 水深反演误差在子图尺度太大时略有增大, 随资料分辨率降低也略有增大.